
一、数据库入门
(一)、数据库介绍
数据库是“按照数据结构来组织、存储和管理数据的仓库”是一个长期存储在计算机内的,有组织的、可共享的、统一管理的大量数据的结合。
分类(1)关系型数据库
(2)非关系型数据库
(二)、用户权限介绍和操作
1.基本操作
注释 “#”
sql以分号“;”为结尾
执行sql语句(闪电&带光标闪电):
1.带光标的闪电:运行光标所在行的sql
2.不带光标的闪电:
a.没有选择任何sql语句的时候,就是从文件的开头执行所以sql语句(如果中间有执行失败的,就停止执行)
b.选择了一条或多条sql语句,就是执行所以选择的sql语句
命名规则:表 t_xxx,列f_xxx
2.数据类型
(1)数值类型
(2)日期和时间类型
(3)字符串类型
char(40):一个字符占一个字节,长度固定是40
如果存“hello”,实际存的是“hello000000……”,如果实际存储数据长度1比40短,剩余长度用0补齐
nchar(40):n代表宽字符集,一个字符占两个字节,长度固定是40,实际占用80个字节空间
varchar(40):最大长度是40,如果存“hello”实际上存的是“hello”,按照实际数据长度分配空间,最长不能超过80
nvarchar(40):n代表宽字符集,一个字符占两个字节空间,最大长度是40
(4)二进制类型
(5)空间类型
(6)JSON 类型
3.建表约束
1)主键:primary key,表中数据唯一的一列,一个表只能有一列是主键列,数据库会根据主键创建索引,根据主键查找快
2)唯一:unique,数据不允许重复,一个表中可以有很多唯一列
3)非空:not null,数据不允许为空
4)默认值:default,用户不填写的时候数据库会自动输入默认值
5)自增:auto_increment,当插入新记录时,不需要手动指定该字段的值,数据库会自动为其分配下一个可用的数字
6)外键约束:外键约束确保了子表中的外键值与主表中的主键值相对应,防止了数据的不一致性。
4.设置默认使用的库(查表的时候就不用专门指定库了,没有指定库的时候就在默认使用的库中查找)
use 2024520test;(三)、数据表创建、删除和修改
1.创建表语法:creat table 表名(列名 数据类型 建表约束,列名 数据类型 建表约束,……);
例:创建一个学生信息表:学号(int 类型,主键,自增),姓名(非空且唯一),年龄(默认18岁),姓名(非男即女)
create table t_student(
num int primary key auto_increment,
name varchar(10) not null unique,
age int default 18,
sex enum('男','女')
);
2.修改表:alter table 表名 ……;
(1)增加列:alter table 表名 add column 列名 数据类型 约束条件;
alter table t_student add column school int;
(2)修改列属性:alter table 表名 modify 列名 数据类型 约束条件;
alter table t_student modify school varchar(15);
(3)删除列:alter table 表名 drop 列名;
alter table t_student drop school;
3.删除表:drop table 表名;
drop table t_student;
(四)、数据库三大范式和BCNF范式
1.数据库常见名词
(1)表中的一列->属性->特征->字段
(2)表中的一行->元组
(3)码:表中唯一确定一个元组的属性,码不止一个,叫这些为候选码
(4)主码:从候选码挑选一个主要确定这一行的属性
(5)主属性:只要在任何一个候选码中出现过,这个属性就叫主属性
(6)非主属性:没有在任何一个候选码中出现过
(7)范式:想要设计一个好的关系,必须使关系满足一定的约束条件,此约束已经形成了规范,按照这种规范可以使设计简洁的、结构明晰、不会因为插入删除,更新数据导致异常。
2.范式
(1)第一范式(1NF):属性不可分
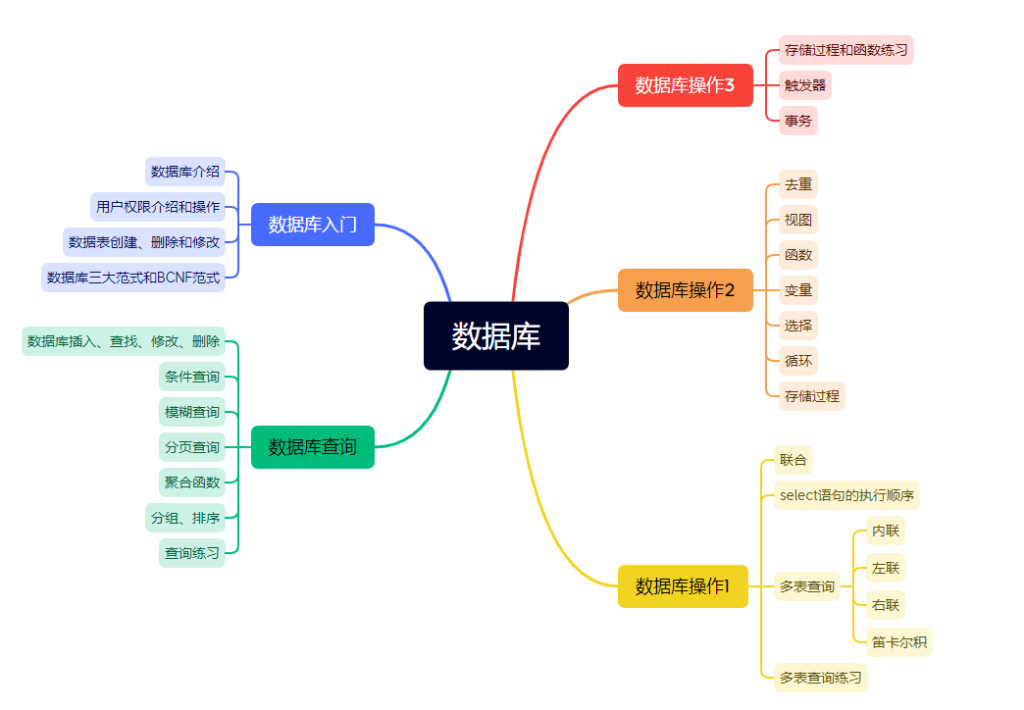
(2)第二范式(2NF):不存在组合关键字中的某些字段决定非关键字段(组合关键字不可拆)

例:选课课表(学号,姓名,年龄,课程名称,成绩,学分)
(学号,课程名称)-->(姓名,年龄,课程名称,成绩,学分)
(学号)-->(姓名,年龄)
(课程名称)-->(学分)
不符合第二范式
修改方案:
学生:学号,姓名,年龄
课程:课程名称,学分
选课:学号,课程名称,成绩
(3)第三范式(3NF):不存在依赖传递
(关键字段-->非关键字段x->非关键字段y)
例:学生的关系表(学号,姓名,年龄,所在学院,学院地址,学院电话)
(学号)-->(学号,姓名,年龄,所在学院)
(学号)-->(所在学院)-->(学院地址,学院电话)
不符合第二范式
修改方案:学生单独一个表(包含学院),学院单独一个表
(4)鲍伊斯-科得范式(BCNF):不存在关键字段决定关键字段
例:仓库管理系统(仓库ID,储存物品ID,管理员ID,数量)
(仓库ID,储存物品ID)-->(管理员ID,数量)
(管理员ID,储存物品ID)-->(仓库ID,数量)
相互决定
不符合BCNF
修改方案:
仓库管理:仓库ID,管理员ID
仓库:仓库ID,储存物品ID,数量
二、数据库查询
(一)、数据库插入、查找、修改、删除
1.查询数据
(1)查看全部列的数据:select * from 表名;
(2)查看部分列的数据:select 列名1,列名2,…… from 表名;
(3)给查询到的列起别名:select 列名1 别名1,列名2 别名2,…… from 表名;
select * from t_student;
select name,sex from t_student;
select name 姓名,sex 性别,age from t_student;
2.插入数据
(1)给所有列插入数据(值的顺序要和表中列的顺序一致):insert into 表名 values (值1,值2,……);
(2)给部分列插入数据(值的顺序要和表中列的顺序一致):insert into 表名(列名1,列名2,……)values(值1,值2,……);
insert into t_student values(10,'逯瑶',21,'女');
insert into t_student (name) values('小陈');
3.更新数据:update 表名 set 列名=新的值 where 条件;
update t_student set age=20;#全部修改,需要修改安全属性
update t_student set age=19 where name='逯瑶';
4.删除数据:delete from 表名 where 条件;
delete from t_student where num=21;
(二)、条件查询
where 条件;
(1)相等:列名=值;
(2)不相等:列名!=值;(只有mysql支持) 列名<>值;
(3)大于,大于等于,小于,小于等于:列名>值; 列名>=值; 列名<值; 列名<=值;
(4)或者:条件1 or 条件2;
(5)并且:条件1 and 条件2;
(6)介于两者之间:between 值1 and 值2;(是闭合区间)
(7)在范围内:in(范围);
(8)不在范围内:not in(范围);
查询年龄小于等于18岁或者性别是男的同学
select * from t_student where age<=18 or sex='男';
查询年龄小于等于18岁并且年龄是男的同学
select * from t_student where age<=18 and sex='男';
查询年龄在18到19岁之间的同学
select * from t_student where age between 18 and 19;
查询学号在1 3 4 5范围内的同学
select * from t_student where num in(1,3,4,5);
查询学号不在1 3 4 5范围内的同学
select * from t_student where num not in(1,3,4,5);
(三)、模糊查询
where 列名 like 模糊表达式
模糊表达式:
%:匹配0-n个字符,例如“张%”,可以匹配“张三”,“张牙舞爪”,“张三丰”,……
_:匹配1个字符,例如“张”,可以匹配“张大”,“张安”,“张三”……
查询名字中带有“雪”字的同学
select * from t_student where name like'%雪%';
(四)、分页查询
limit a,b;(a:起始行数,从0开始 b:显示多少行)
select * from t_student limit 2,4;已知当前第几页,每页显示x行alter
select * from t_student limit (n-1)*x,x;
(五)、聚合函数
(1)统计个数:count()
select count(*) from student;(2)求和: sum()
查询01同学的总成绩
select sum(score) from sc where S='01';(3)计算最大值:max()
查询01课程的最高分
select max(score) from sc where S='01';(4)计算最小值:min()
查询02课程的最低分
select min(score) from sc where S='02';(5)计算平均分:avg()
查询03课程的平均分
select avg(score) from sc where S='03';(六)、分组、排序
1.group by 条件;
查询每门课程的平均分
select C,avg(score) from sc group by C;查询每名同学的总成绩
select S,sum(score) from sc group by S;查询总成绩大于200的学生的编号和总成绩
select S,sum(score) from sc group by S having sum(score)>200;2.where和having的区别:
作为条件的列是表中原来就有的,使用where来加条件
作为条件的列不是表中原来就有的,使用having加条件
3.排序
order by 列名 排序规则(asc/desc,不写排序规则默认升序排序)
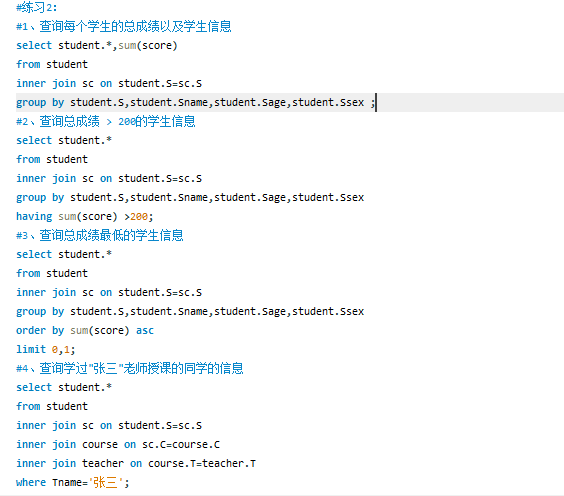
(七)、查询练习

三、数据库操作1
(一)、多表查询
1.内联:select * from 表1 inner join 表2 on 连接条件 inner join 表3 on 连接条件……;
2.左联:select * from 表1 left join 表2 on 连接条件;
3.右联:select * from 表1 right join 表2 on 连接条件;
4.笛卡尔积:select * from 表1,表2 where 连接条件;
(二)、多表查询练习
四、数据库操作2
(一)、去重
(按照行去除重复数据:distinct)
select s from sc;
select distinct s from sc;(二)、视图
为了简化复杂的select语句而提出的概念。视图是一个表或者多个表导出的虚拟表。不是真实存在的。不需要满足范式的要求
创建视图:create view 视图名 as (select 语句);
使用视图:按照表的方式
删除视图:drop view 视图名
create view myview as(
select student.*,C,score from student inner join sc on sc.S=student.S
);
select *from myview;
drop view myview;视图的优点和缺点
优点:sql语句在网络中传输,使用视图可以减少流量,更安全
缺点:执行效率并没有提高,实际执行的还是原来的语句
(三)、函数
创建函数:
delimiter // #声明//为新的sql语句结束标志--从此开始;就不再是sql语句的结束标志
create function 函数名(参数名1 数据类型,参数名2 数据类型,……)
returns 返回值类型
begin
函数体sql;
函数体sql;
……
end//
delimiter ; #重新声明;为sql语句的结束标志
使用函数:
select 函数名(参数列表);
删除函数:
drop function 函数名;(如果函数名不存在,删除的时候会报错)
先判断函数是否存在再删除:drop function if exists 函数名;
实现一个加法函数
drop function if exists myadd;
delimiter //
create function myadd(a int,b int)
returns int
DETERMINISTIC
begin
declare c int default 0;
set c = a + b;
return c;
end //
delimiter ;
select myadd(2,5);(四)、变量
局部变量:函数内部使用的
会话变量:生命周期就是整个会话
set @x=10;
select @x;
系统变量(全局变量):声明周期是整个操作系统,不能自己定义,只有root用户有操作权限
查看所有系统变量
show global variables;
查询单个系统变量的值
select @@connect_timeout;
(五)、选择
if判断语法:
if(表达式1) then 执行语句1;执行语句2;执行语句3;
elseif(表达式2) then 执行语句1;执行语句2;执行语句3;
else 执行语句1;执行语句2;执行语句3;
end if;
case判断语法1:
case 变量 when 值1 then 执行语句;
when 值2 then 执行语句;
when 值3 then 执行语句;
end case;
case判断语法2:
case when (表达式1) then 执行语句;
when (表达式2) then 执行语句;
when (表达式3) then 执行语句;
end case;
定义一个函数,判断输入的值是正数、负数、还是零
drop function if exists myfun;
delimiter //
create function myfun(n int)
returns varchar(5)
DETERMINISTIC
begin
declare res varchar(5) default '';
if(n>0) then set res='正数';
elseif(n=0) then set res='零';
else set res='负数';
end if;
return res;
end //
delimiter ;
select myfun(-10);drop function if exists myfun;
delimiter //
create function myfun(n int)
returns varchar(5)
DETERMINISTIC
begin
declare res varchar(5) default '';
case when (n>0) then set res='正数';
when (n=0) then set res='零';
when (n<0) then set res='负数';
end case;
return res;
end //
delimiter ;
select myfun(0);(六)、循环
while循环语句
while 条件
do
执行语句;
end while;
mysql中没有for循环,但是有repeat和loop循环
实现一个函数,计算1+2+3+……+n
drop function if exists mysum; delimiter // create function mysum(n int) returns int DETERMINISTIC begin declare i int default 1; declare sum int default 0; while i<=n do set sum=sum+i; set i=i+1; end while; return sum; end // delimiter ; select mysum(10);
五、数据库操作3
(一)、存储过程:procedure
大型数据库中,一组为了完成特定功能的sql集合。存储在数据库中,一次编译永久有效
优点:
减少网络流量:存储过程直接在服务端运行,减少和客户机的交互
增强代码的重要性和共享性
加快系统运行速度
使用灵活
创建语法:
delimiter //
create procedure 过程名(参数1 类型,参数2 类型,……)
begin
执行语句;
执行语句;
end//
delimiter ;
注意:
存储过程没有返回值,可以通过参数返回数据,参数可以为IN|INOUT|OUT类型,不写默认是IN类型
执行存储过程: call 存储过程名(参数列表)
删除:
drop procedure if exists 存储过程名
例:
drop procedure if exists mypro;
delimiter //
create procedure mypro()
begin
select student.*,C,score from student inner join sc on sc.S=student.S;
end //
delimiter ;
call mypro();存储过程和函数的区别:
1.函数有返回值,存储过程没有返回值,但是可以通过参数返回数据;
2.函数只能操作数据,函数中不能有sql语句,存储过程中可以有sql语句
(二)、触发器:trigger
是特殊的存储过程,当指定事件(修改、插入、删除)发生的时候、系统自动调用
创建语法:
delimiter //
create trigger 触发器名字 #创建触发器,没有参数
after或者begin操作名字 #在……操作之前或者之后
on 表名 #对哪个表进行操作
for each row #影响每一行
begin
执行语句;
end //
delimiter ;
删除语法:
drop trigger if exists 触发器名字;
例子:当修改student表的学生编号的时候,自动修改sc表中对于学生的编号
drop trigger if exists myupdate;
delimiter //
create trigger myupdate
after update
on student
for each row
begin
#修改sc表中对应学生的编号
update sc set S=new.S where S=old.S;
#new表:装的是修改之后的数据,或者是新插入的数据
#old表:装的是修改之前的数据,或者是删除的数据
end //
delimiter ;update student set S='100' where S='01';
(三)、事务
create table bank(
name varchar(45),
money double
check(money>=0) #check在mysql是无效的
);
insert into bank values('小逯',100);
insert into bank values('小瑶',0);
select *from bank;
小逯向小瑶借了50元
update bank set money=money-50 where name='小逯';
update bank set money=money+50 where name='小瑶';
事务是作为单个逻辑工作单元执行的一系列sql语句,要么都执行成功,要么都不执行
特性:
原子性:事务是最小的工作单位,不可再分,要么都执行,要么都不执行
一致性:数据库完整性约束不会被破坏
隔离性:并行执行的事务,相互之间是隔离的
持久性:事务的修改提交以后,永久保存在本地
开启事务:start transaction;
执行一列sql语句;
执行一列sql语句;
执行一列sql语句;
二选一
1.回滚:rollback #刚刚执行的一系列sql语句对数据的修改错误,数据回退到开启事务之前的状态
2.提交:commit #刚刚执行的一系列sql语句对数据的修改正确,保存起来,其他用户查询到结果是保存以后的结果
start transaction;
update bank set money=money-50 where name='小逯';
update bank set money=money+50 where name='小瑶';
rollback;
commit;
Comments NOTHING